GuanceDB Metrics Storage - No More Disk Space
Incident Summary
Date: 11/07/2025
Cluster: id1 prod
Status: Resolved
Brief Description
NSQ df_metric_guance channel piled up. Investigation revealed that guancedb-storage disk was completely full, preventing any new data writes. The issue was resolved by expanding the disk space allocation.
Impact
- No impact on user data integrity and no data loss as well
- For 30 minutes users weren't able to see the metrics data written in that period of time
Timeline
Incident Start
- 10:05 - GuanceDB storage disk reaches capacity, service switches to read-only mode
- 10:05 - kodo-x (metrics worker) and GuanceDB Metrics QPS drop to zero
Detection & Alert
- 10:27 - NSQ pile up for
df_metric_guancefires alert to Lark channel - 10:27 - Investigation begins
Investigation
- 10:27-10:30 - Checked monitoring charts, confirmed zero QPS for both kodo-x and GuanceDB since 10:05
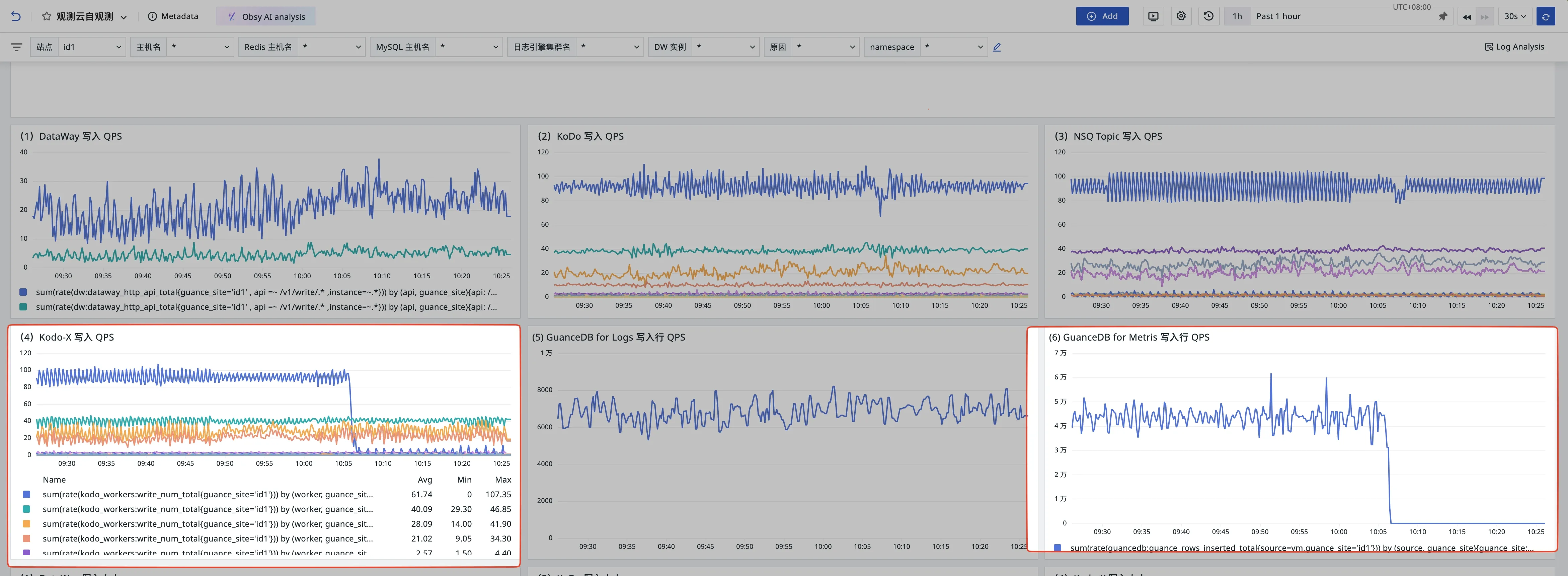
- 10:30 - Examined guance-insert-for-metrics logs, found writing failures to guance-storage
- 10:30 - Checked guancedb-storage logs, discovered disk space exhaustion:
text
'ts": "2025-07-1102:05:43.8607" ,
"level": "warn",
"caller": "gitlab.jiagouyun.com/guance/guancedb/metricstore/storage.go:714",
"msg":"switching the storage at /storage to read-only mode, since it has less than -storage.minFreeDiskSpaceBytes=10000000 of free space: 8454144 bytes left"Resolution
- 10:30-10:34 - Increased PVC capacity via Rancher UI, edit the two PVC yaml file, changed
spec.resources.requests.storagefrom 20Gi to 40Gi - 10:34 - Verified
/storagedisk expanded to 40Gi usingdf -h - 10:34 - Confirmed recovery: NSQ pile decreasing, guancedb-insert and kodo-x QPS returned to normal
Incident End
- 10:34 - All systems operating normally, incident resolved
Total Duration: 29 minutes (10:05 - 10:34)
Detection Delay: 22 minutes (10:05 - 10:27)
Root Cause Analysis
The GuanceDB storage service reached 100% disk capacity, preventing the ingestion component from writing new metrics data.
the datakit collector has a bug, whereas the collector couldn't collect disk related metrics from guance-storage pod, thus the alert for "almost full disk space" weren't triggered
What Could Be Improved
- the storage was full since 10:05, and we only get the alert message at 10:27, which was the failure message of upstream services. this MTTR is way to long
Next Step
- [ ] Review and understand why disk related metrics was not collected in the first place.
- [ ] Guance-insert/kodo-x(metrics worker) had zero QPS, why wasn't there an alert for that